


Table of contents
- This episode: Amazon Athena. In this Hello, Cloud blog series, we're covering the basics of AWS cloud services for newcomers who are .NET developers. If you love C# but are new to AWS, or to this particular service, this should give you a jumpstart.
- Amazon Athena: What is it, and why use It?
- Our Hello, Athena Project
- One-time Setup
- Step 7: Shut it Down
- Where to Go From Here
- Further Reading
This episode: Amazon Athena. In this Hello, Cloud blog series, we're covering the basics of AWS cloud services for newcomers who are .NET developers. If you love C# but are new to AWS, or to this particular service, this should give you a jumpstart.
In this post we'll introduce Amazon Athena and the concept of data lakes, create a "Hello, Cloud" use of Athena, and use it in a .NET program. We'll do this step-by-step, making no assumptions other than familiarity with C# and Visual Studio. We're using Visual Studio 2022 and .NET 6.
Amazon Athena: What is it, and why use It?
Amazon Athena is "an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL." Let that sink in: you get to use SQL to query data, but here the data is not in a database, it's in S3--in other words, you're querying against files.
To understand Athena, we first need to talk about data lakes. A data lake is a place you can put your structured and unstructured data, without having to change it. Data lakes are increasingly popular in the era of big data, and are particularly suited to organizations that need to mine their data and make decisions from it in its present form. The data in a data lake can come from people, mobile devices, applications, server logs, and/or IoT devices such as factory sensors.
In AWS, an S3 bucket is the store for a data lake, and the data can be in the form of JSON files, Parquet files, and delimited files such as comma-separated values (CSV) and tab-delimited values (TSV). The data will grow, because a data lake is a living thing. If you're used to having your information in well-structured databases, a data lake might seem like a very messy thing in comparison. As organizations cast an ever-wider net to increase their awareness, much of that data is going to be loose, mixed, and voluminous. We need different tools and approaches to work in this maelstrom, where data is rushing in at a furious pace and needs to be rapidly analyzed.
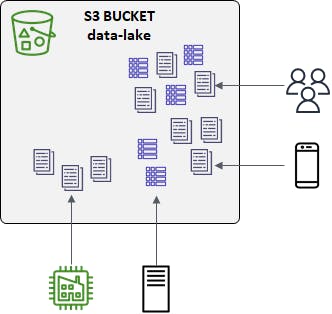
With a data lake, you can query, analyze, visualize, and run machine learning against your data as-is. Multiple AWS services perform those functions. Amazon Athena is for querying your data lake. You define table schema for one of more subsets of your data lake, for example server log TSV files or expense report CSV files, and after that you can query those tables.
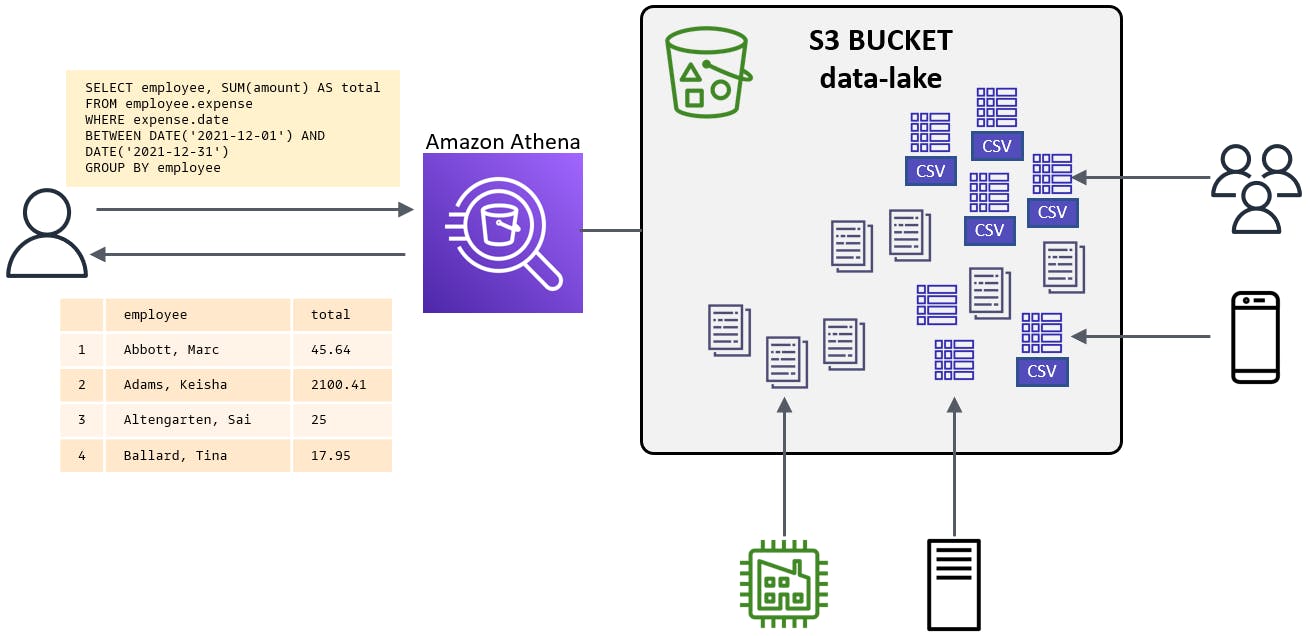
Our Hello, Athena Project
We’re going to create a data lake and upload expense report CSV files to it. Next, we'll teach Athena to understand the data and query the data from the AWS console. Finally, we'll create a .NET console program that queries the data with Athena via the AWS SDK for .NET.
One-time Setup
To experiment with Amazon Athena and .NET, you will need:
- An AWS account, and an understanding of what is included in the AWS Free Tier.
- Microsoft Visual Studio 2022. If you're using an older version of Visual Studio you won't be able to use .NET 6.
- AWS Toolkit for Visual Studio. Configure the toolkit to access your AWS account and create an IAM user.
Step 1: Set Permissions for the AWS User
The IAM user for your AWS toolkit user / AWS default profile needs a policy with the necessary permissions to interact with AWS services programmatically. In this step, you'll give that user the built-in PowerUserAccess policy, intended for developers. If you've done other exercises in the Hello, Cloud blog series, you may have already set up this permission.
Important: You should always follow the principle of least privilege when it comes to security. This blog series assumes you are working in your own developer account for learning purposes and not working with anything production-related. If you're using an organization-owned AWS account, you should coordinate with your security principal on IAM settings.
- In the AWS console, navigate to the Identity and Access Management (IAM) area of the AWS Console. You can enter iam in the search box to find it.
- Navigate to IAM > Users and select the username you use with the AWS Toolkit for Visual Studio (you created this user when you installed and configured the toolkit).
- If not already assigned, attach the built-in PowerUserAccess policy. The PowerUserAccess permission provides developers full access to AWS services and resources, but does not allow management of users and groups.
Your AWS Toolkit for Visual Studio user now has the permissions it needs to interact with S3 and Athena.
Step 2: Create S3 Buckets and Upload Expense Files
In this step, we'll create an S3 bucket for our data lake and upload expense report files to the data lake. We'll also create a second S3 bucket to hold Athena query results.
- Navigate to the AWS console and sign in.
- Set the region at top right to the region you want to be working in. We're using us-west-1 (N. California).
- Navigate to S3. You can enter s3 in the search bar.
- Select Buckets in the left panel.
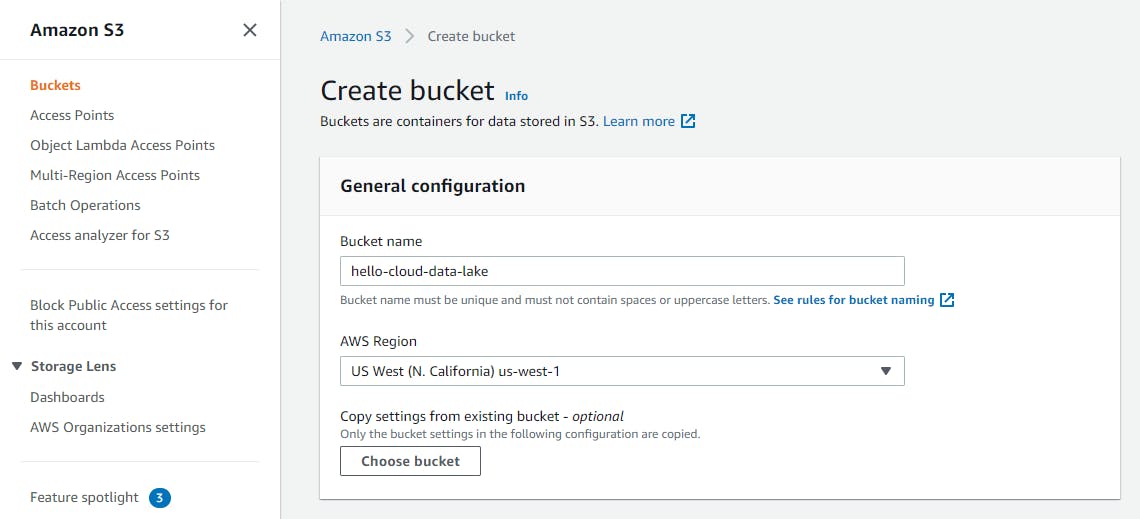
- Click the Create bucket button at right.
- For Bucket name, enter a bucket name you want to use for a data lake. We're using hello-cloud-data-lake. Replace that with your bucket name in the remaining steps. This is your data lake bucket, make a note of the name.
- Click Create bucket at bottom. The new bucket is created and visible in the console.
- Repeat steps 5-7 to create another bucket for query results. We're using hello-cloud-athena. This is your Athena query bucket. Make a note of the name.
- Click your data lake bucket name link to view its contents. It is empty.
- On your local computer, create a text file named expenses-marc-abbott.csv with the contents below.
Marc Abbott,2021-12-01,25.65,Office supplies - printer paper Marc Abbott,2021-12-01,19.19,Office supplies - stapler - Create a second text file named expenses-keisha-adams.csv with the contents below.
Keisha Adams,2021-12-01,1100.00,sewing machine repair Keisha Adams,2021-12-05,100.00,fabric Keisha Adams,2021-12-08,100.00,fabric Keisha Adams,2021-12-12,100.00,fabric Keisha Adams,2021-12-19,100.00,fabric Keisha Adams,2021-12-26,100.00,fabric Keisha Adams,2021-12-27,100.00,fabric Keisha Adams,2021-12-27,100.00,fabric Keisha Adams,2021-12-28,100.00,fabric Keisha Adams,2021-12-30,100.00,fabric Keisha Adams,2021-12-13,100.00,fabric - Create a third text file named expenses-sai-altengarten.csv with the contents below.
Sai Alterngarten,2021-12-13,10.00,sewing machine needle Sai Alterngarten,2021-12-25,15.00,sewing cushion - Create a fourth text file named expenses-tina-ballard.csv with the contents below.
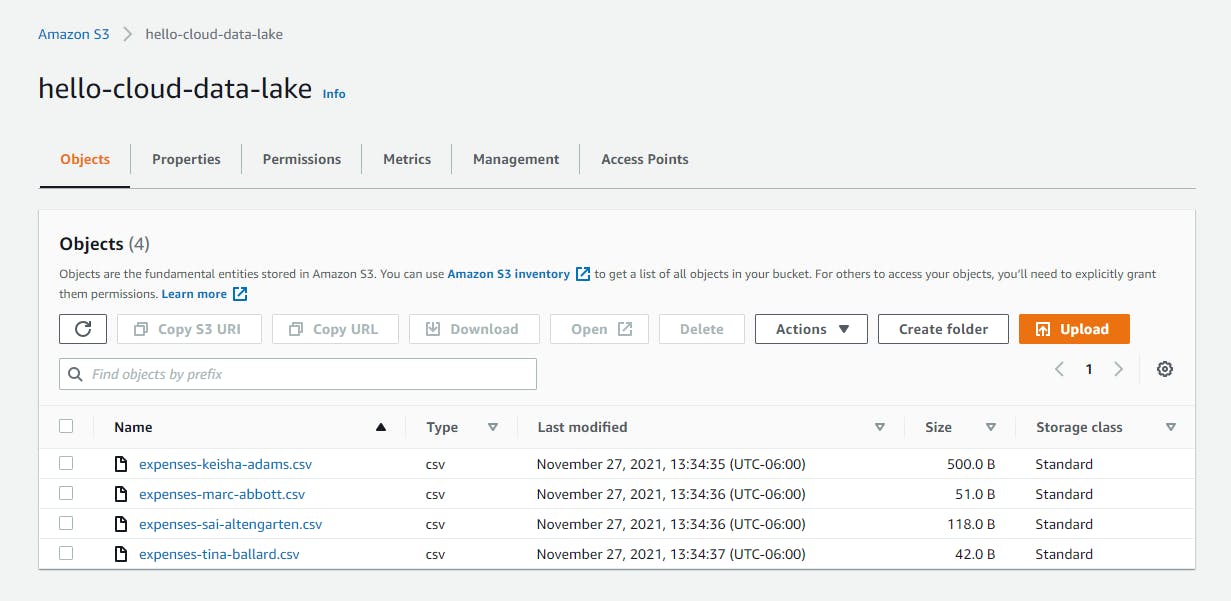
Tina Ballard,2021-12-03,17.95,lunch - In the AWS console, navigate to S3 > Buckets, click on the data lake bucket name you created above in #6, and click the Upload button. Select the 4 .csv files you just created and click the Upload button at bottom. Click Close to dismiss the confirmation dialog. The 4 .csv file objects should now be visible in the AWS console.
Step 3: Create Database and Table in Athena
In this step you'll configure Athena to understand the expense report CSV files by defining a database and a table.
- In the AWS console, navigate to Amazon Athena. You can type athena in the search box.
- Click Query editor on the left panel.
- Click the View Settings button at top right.
- On the Settings tab, click Manage.
Click the Browse S3 button and select the Athena query bucket you created earlier in Step 2, sub-step #8.
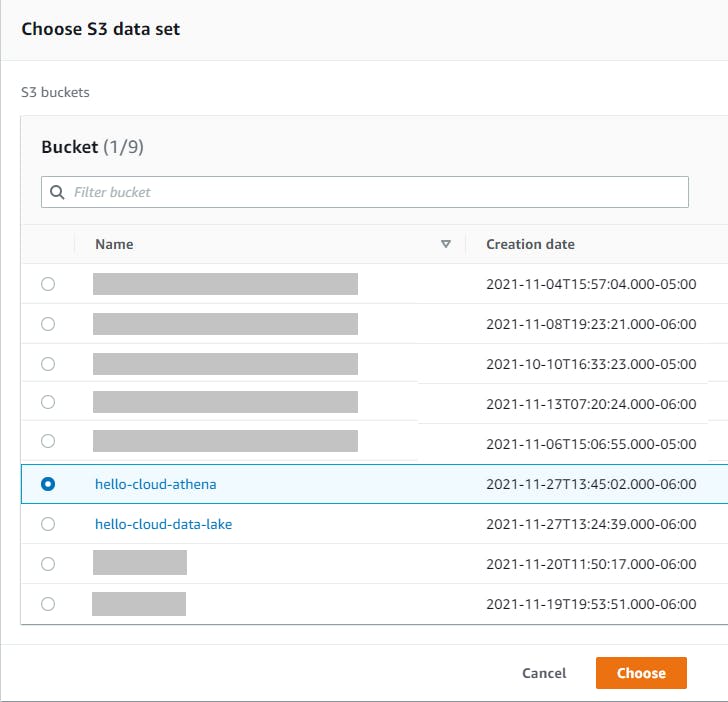
Click Save.
- Select the Editor tab.
In the Query pane, enter the query below.
CREATE DATABASE employeeClick Run to create the Athena database.
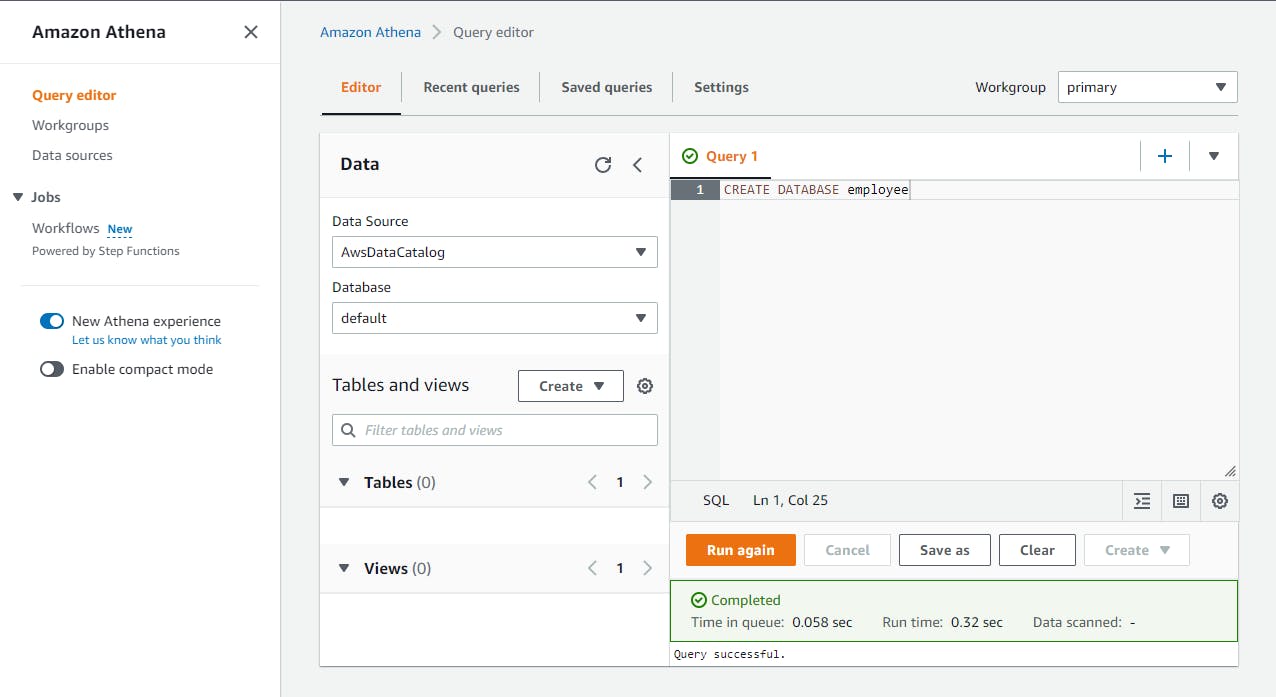
There should now be an employee choice listed in the Database dropdown at left. Select it.
Next, we'll define a table and relate it to the structure of our employee expense CSV files. In the query pane, enter the query below.
CREATE EXTERNAL TABLE IF NOT EXISTS expense ( employee STRING, `date` DATE, amount DECIMAL(8,2), reason STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' LOCATION 's3://hello-cloud-data-lake/';The CREATE EXTERNAL TABLE query identifies the S3 bucket to use as a data source, specifies four fields with names and data types, and indicates the file format: delimited, with fields separated by commas and rows separated by newlines. "date" is surrounded by the backtick character because it is a reserved word.
Click Run to create the table.
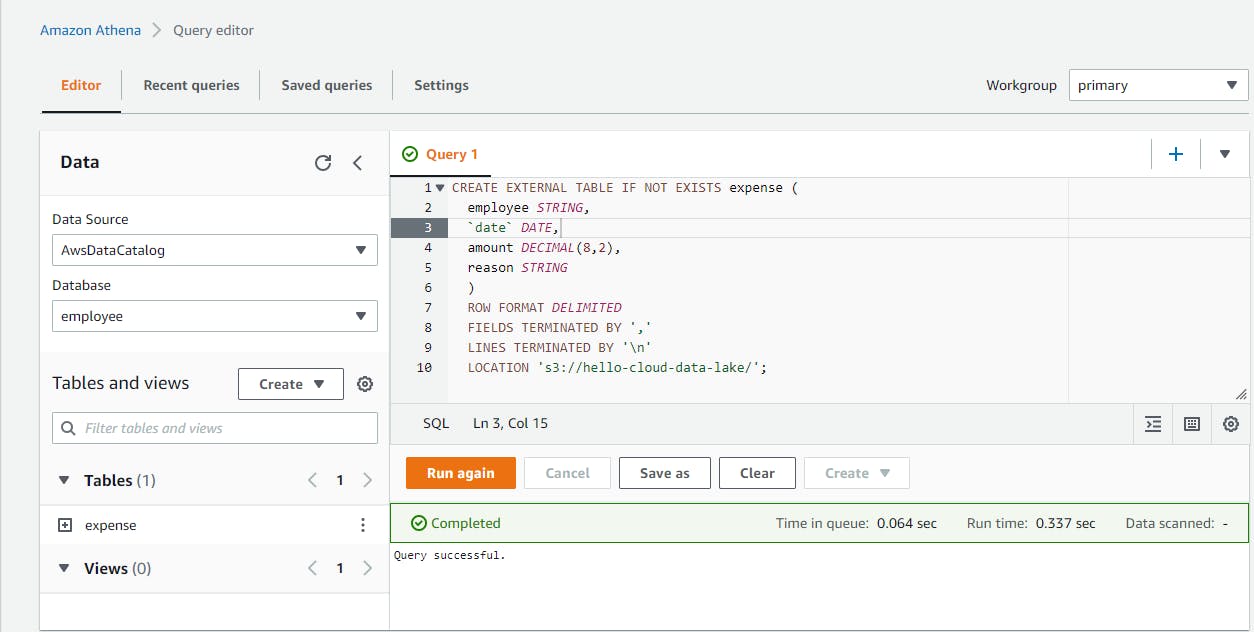
There should now be a table listed named expense
Expand the expense item under Tables and see the field definitions.
Step 4: Query the Expense Table
In this step, you'll query the expense reports in your data lake using Athena.
In the query pane, enter the query below.
SELECT * FROM expenseClick Run and wait for the query results. You see the individual expense records drawn from the CSV files in S3.
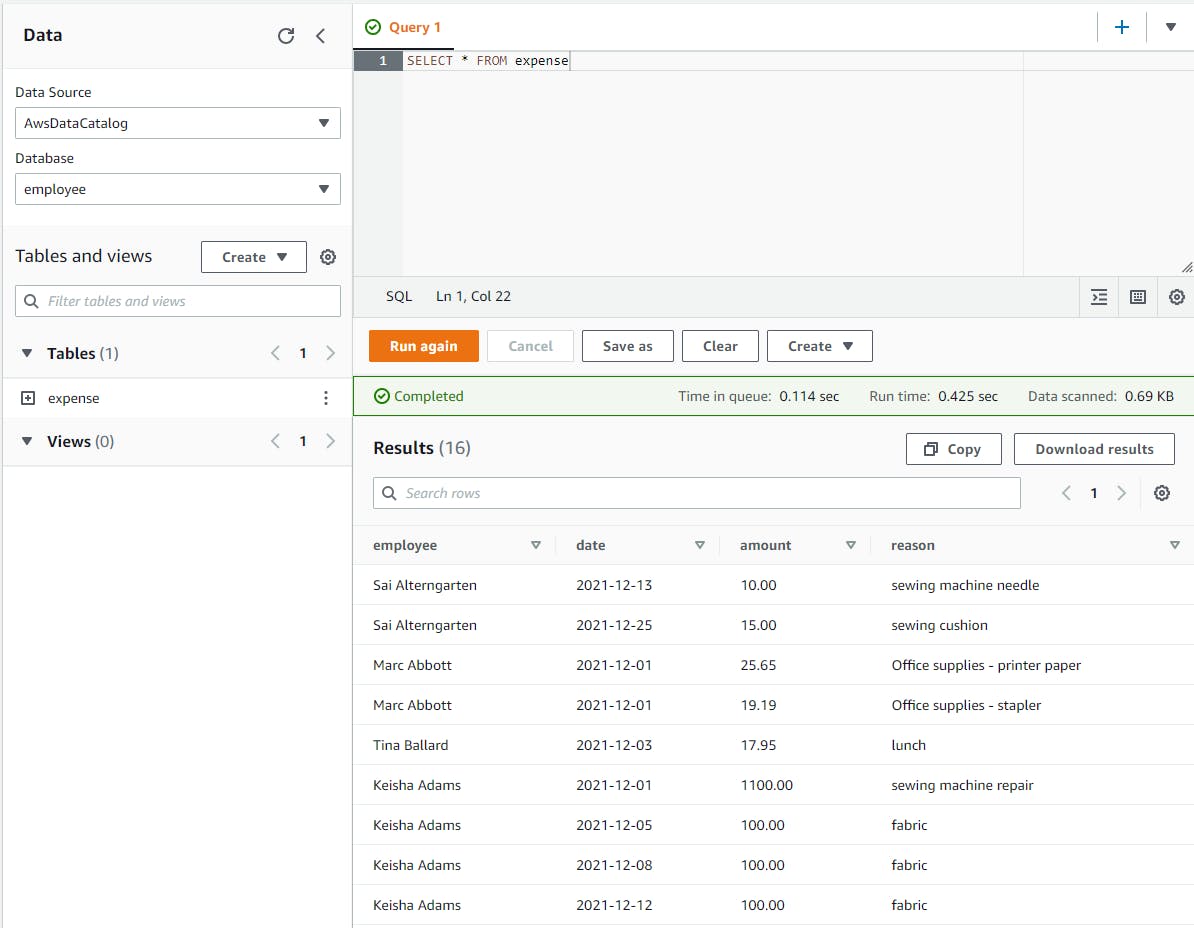
In the query pane, enter the query below.
SELECT employee, SUM(amount) AS total FROM employee.expense WHERE expense.date BETWEEN DATE('2021-12-01') AND DATE('2021-12-31') GROUP BY employeeClick Run and wait for the query results. Now you see expense totals grouped by employee.
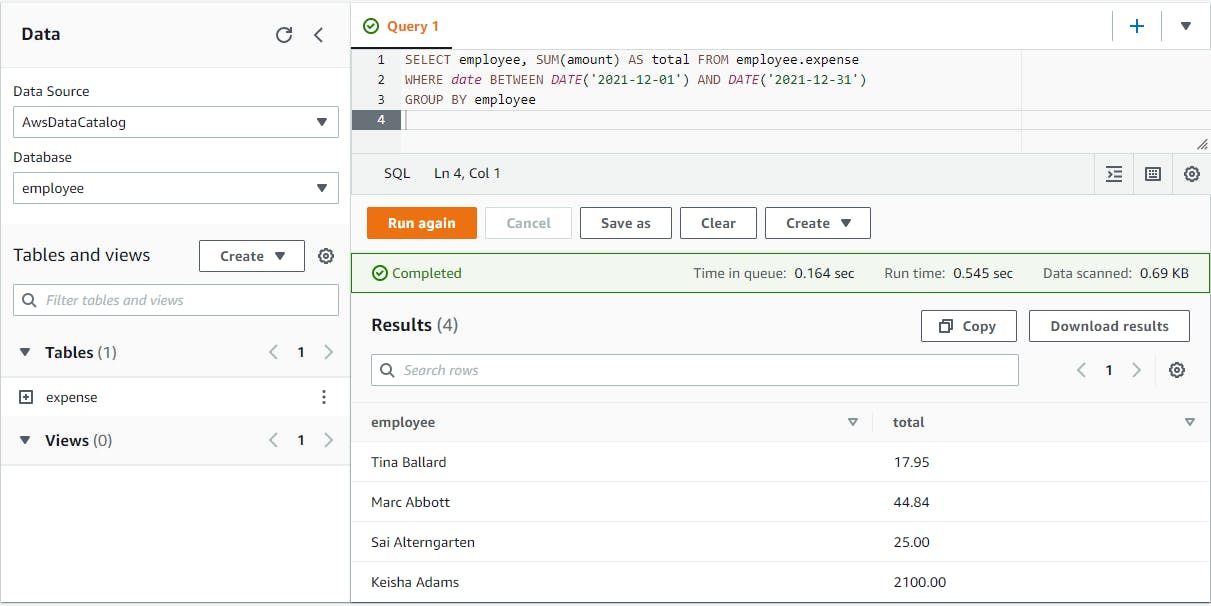
If you'd like to save your query for the future, click the Save as button, give your query a name, and click Save query.
 Your saved queries are listed on the Saved queries tab.
Your saved queries are listed on the Saved queries tab.
What dialect of SQL is this? Athena uses PrestoDB.
Optional: Feel free to experiment. Add/modify your expense CSV files, upload to S3, then re-run these queries. Try other Presto SQL queries.
Step 5: Query Athena from a .NET Program
You can invoke Athena queries programmatically from your .NET programs using the AWS SDK for .NET. In this step, you'll write a .NET console program to query your data lake.
Open a command/terminal and CD to your development folder.
Create a new folder named hello-athena and CD to it.
Use the dotnet new console command to create a new console program.
dotnet new console
Launch Visual Studio and open the hello-athena project.
In Solution Explorer, right-click the hello-athena project and select Manage NuGet Packages....
On the Browse tab, enter awssdk.athena.
Select AWSSDK.Athena and click Install to install the package.
Edit Program.cs, and replace it with the code at the end of this step. We'll explain how this code works after we see it run.
Change the bucket name in line 26 to your Athena query bucket that you created in Step 2.
Save your changes and Build the project.
From your command line prompt, CD to the hello-athena project folder, and run the project with dotnet run:
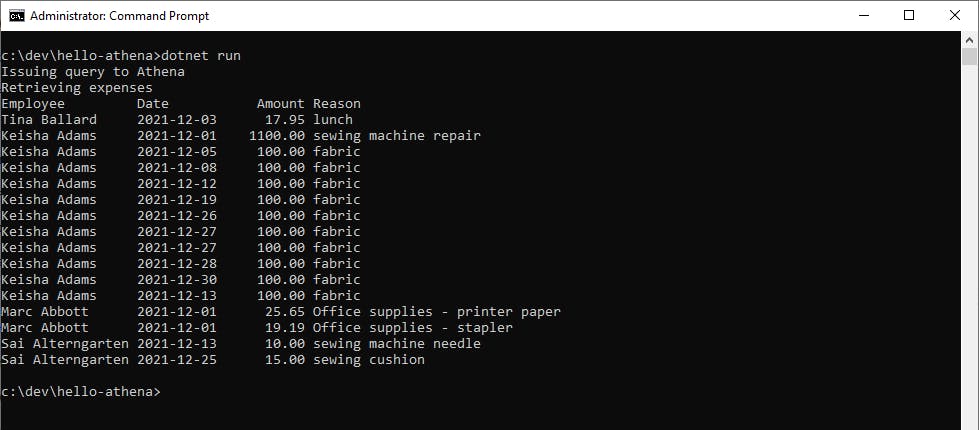
You see the list of employee expenses return by Athena, sourced from the expense report CSV files in your S3 data lake. Congratulations!
Program.cs
using Amazon.Athena;
using Amazon.Athena.Model;
public class Program
{
static AmazonAthenaClient _client = null!;
const int EmployeeIndex = 0, DateIndex = 1, AmountIndex = 2, ReasonIndex = 3;
static async Task Main(string[] args)
{
Console.WriteLine("Issuing query to Athena");
_client = new AmazonAthenaClient(Amazon.RegionEndpoint.USWest1);
var queryRequest = new StartQueryExecutionRequest
{
QueryString = "SELECT employee,date,amount,reason from employee.expense",
QueryExecutionContext = new QueryExecutionContext()
{
Database = "employee"
},
ResultConfiguration = new ResultConfiguration
{
OutputLocation = "s3://hello-cloud-athena/"
}
};
var result = await _client.StartQueryExecutionAsync(queryRequest);
// Retrieve results
Console.WriteLine("Retrieving expenses");
GetQueryResultsResponse results = null!;
bool firstTime = true;
string token = null!;
Row index = null!;
string queryExecutionId = result.QueryExecutionId;
while (firstTime || token != null)
{
token = (firstTime ? null! : token);
results = await GetQueryResult(queryExecutionId, token);
int skipCount = 0;
if (firstTime)
{
skipCount = 1;
index = results.ResultSet.Rows[0];
}
Console.WriteLine($"Employee Date Amount Reason");
foreach (var exp in results.ResultSet.Rows.Skip(skipCount))
{
Console.WriteLine($"{exp.Data[EmployeeIndex].VarCharValue,-16} {exp.Data[DateIndex].VarCharValue,-12} {exp.Data[AmountIndex].VarCharValue,8} {exp.Data[ReasonIndex].VarCharValue}");
}
token = results.NextToken;
firstTime = false;
}
}
/// <summary>
/// GetQueryResult: Await and return Athena query result. If query is still executing, sleeps and retries up to 10 times.
/// </summary>
/// <param name="queryExecutionId">Athena query execution Id</param>
/// <param name="token">continuation token (should be null the first time)</param>
/// <returns>GetQueryResultsResponse object</returns>
static async Task<GetQueryResultsResponse> GetQueryResult(string queryExecutionId, string token)
{
GetQueryResultsResponse results = null!;
bool succeeded = false;
int retries = 0;
const int max_retries = 20;
while (!succeeded)
{
try
{
results = await _client.GetQueryResultsAsync(new GetQueryResultsRequest()
{ QueryExecutionId = queryExecutionId, NextToken = token });
succeeded = true;
}
catch (InvalidRequestException ex)
{
if (ex.Message.EndsWith("QUEUED") || ex.Message.EndsWith("RUNNING"))
{
Thread.Sleep(1000 * 30);
retries++;
if (retries >= max_retries) throw ex;
}
else
{
throw ex;
}
}
}
return results;
}
}
Code Walk-Through
At the top of Program.cs are using statements for the Amazon.Athena namespaces that correspond to the AWSSDK.Athena NuGet package.
line 8: The constants are column indexes which will be used in extracting query result fields.
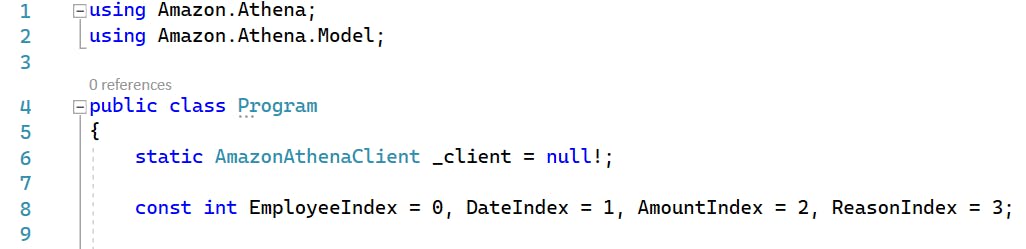
14: The code in Main instantiates an AmazonAthenaClient, which is how we'll communicate with Athena.
16-28: a StartQueryExecutionRequest object is created, which includes the query we want to execute, the database we wish to query, and the S3 Athena query bucket (not the data lake bucket). How does Athena know where the data lake bucket is? We told Athena that when we created the expense table back in Step 3. When our query references employee.expense, Athena knows where that data is from our table definition.
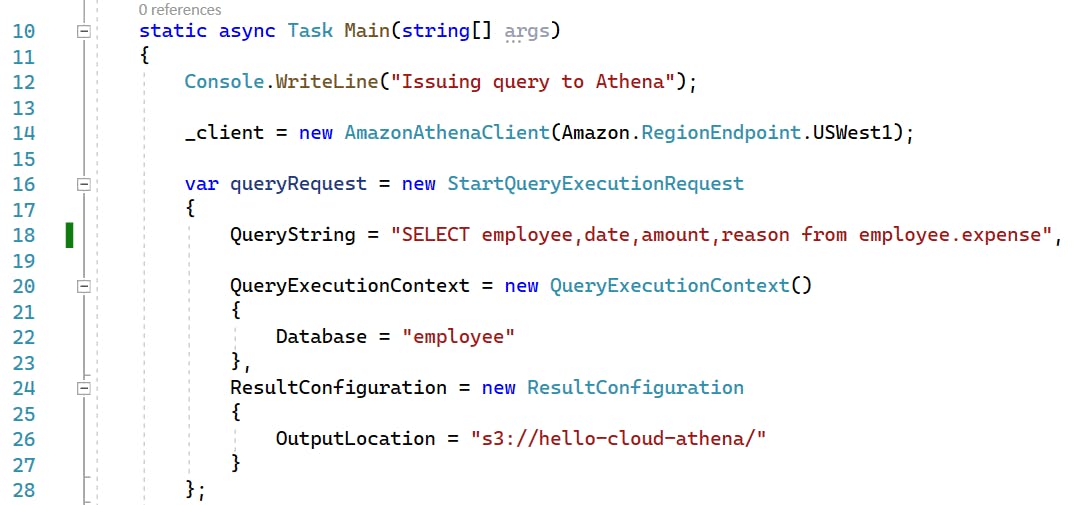
30: We invoke the client's StartQueryExecutionAsync method with the query request, receiving back a StartQueryExecutionResponse. This does not mean the query is finished, only that it has been initiated. The response contains the query execution ID we need to retrieve the query results.
36-62: Athena results from the SDK might come back in multiple chunks, since we don't know in advance how big the result set is. We use a while loop to call a local method named GetQueryResult to get the next set of results, specifying the query execution ID and a continuation token, which is null the first time. The continuation token is how we indicate which result page we want. At the bottom of the while loop, we get the NextToken property of the current response to get the continuation token for the next iteration's call to GetQueryResult. When it isn't our first time through the loop and the continuation token is null, we're done and the while loop exits.
Within the while loop, the response from GetQueryResult is a GetQueryResultsResponse object, whose ResultSet.Rows property contains a collection of Row objects. As we iterate through the rows, we skip over the first row of the first batch of results because it is a header row with field names. We extract our employee name, date, amount, and expense reason from each row using the index constants declared in line 8.
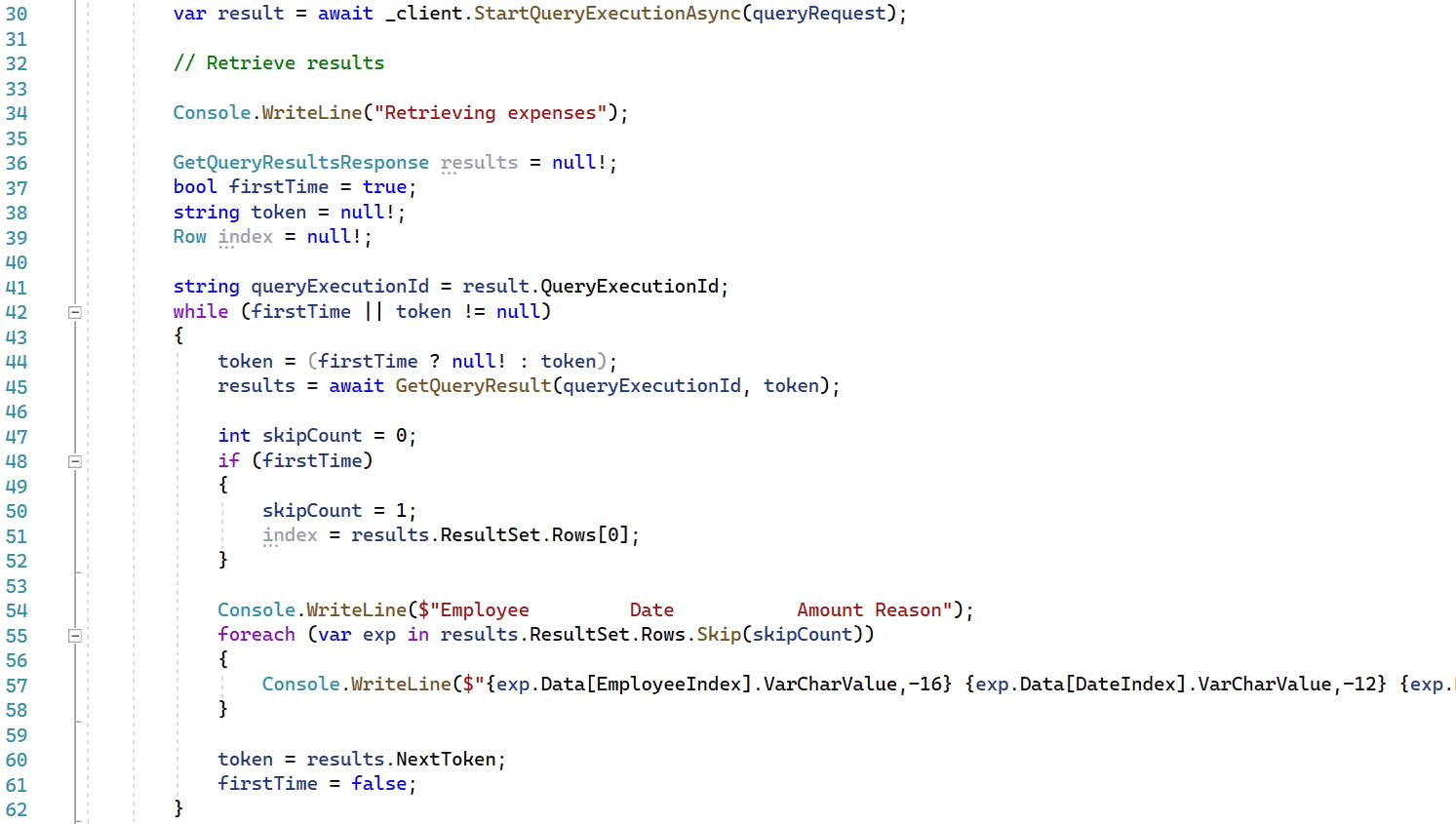
62-103: The GetQueryResult local method calls the Athena client's GetQueryResultsAsync method on our behalf. The response doesn't always return data, as the query may not have finished yet or may not even have started. If a response isn't ready, an exception is thrown. The exception handler checks for statuses QUEUED and RUNNING and sleeps-and-retries in those cases.

Step 7: Shut it Down
When you're finished with it, delete the Athena table/database and S3 objects/buckets. You don't want to accrue charges for something you're not using.
In the AWS console, navigate to the Athena query editor.
Run this Athena query to delete the expense table:
DROP TABLE expenseRun this Athena query to delete the employee database:
DROP DATABASE employeeNavigate to the S3 area of the AWS console.
On the Buckets page, view the bucket for your data lake.
Delete all objects in the bucket, and then the bucket itself.
View the bucket for Athena queries.
Delete all objects in the bucket, and then the bucket itself.
Where to Go From Here
In this exercise, you learned about data lakes and saw how to train Amazon Athena to understand expense report CSV files in S3, allowing you to query them with SQL. Think of the additional kinds of data this puts in reach for analytics. You can analyze uploads from Internet of things (IoT) devices or mobile apps. You can process human-authored data like spreadsheets. You can parse load balancer logs to analyze load or profile DDOS attack traffic.
To work with data lakes for real, you'll want to read up on them and understand where they're appropriate vs. data warehouses, databases and other data tools. To get the most from a data lake, you need metadata and process automation to fish value from it. Lack of that can result in a data swamp, a useless accumulation of data. The AWS documentation resources below explain data lakes and related concepts, and the roles of various AWS analytics services.
As you've seen, Amazon Athena is very easy to get started with. Read the documentation to understand your options for parsing different kinds of S3 files, including Using a SerDe (serializer/deserializer). Presto SQL is probably a little different from other SQL dialects you are familiar with. The best way to get fluent with it is to practice using it and reference the documentation to get the syntax right. Go after some real data you want to query and see what insights come out of it.
You also interacted with Athena from a .NET console program. From here, you might consider building an AWS Lambda function that queries Athena and generates some kind of output like a report. You could trigger that Lambda function to run upon a new S3 upload to your data lake bucket.
Further Reading
AWS Documentation
Amazon Athena Getting Started Tutorial
Using a SerDe (Serializer/Deserializer)
Presto SQL
Blogs