


Table of contents
- This episode: Amazon Textract. In this Hello, Cloud blog series, we're covering the basics of AWS cloud services for newcomers who are .NET developers. If you love C# but are new to AWS, or to this particular service, this should give you a jumpstart.
- Amazon Textract: What is it, and why use It?
- Our Hello, Textract Project
- One-time Setup
- Where to Go From Here
- Further Reading
This episode: Amazon Textract. In this Hello, Cloud blog series, we're covering the basics of AWS cloud services for newcomers who are .NET developers. If you love C# but are new to AWS, or to this particular service, this should give you a jumpstart.
In this post we'll introduce Amazon Textract and use it in a "Hello, Cloud" C# program to extract text from documents and images. We'll do this step-by-step, making no assumptions other than familiarity with C# and Visual Studio. We're using Visual Studio 2022 and .NET 6.
Amazon Textract: What is it, and why use It?
Hidden in a long text, there are perhaps three lines that count. — Alexander Kluge
Amazon Textract is a service that can automatically extract text and data from documents. AWS describes it as "a machine learning (ML) service that automatically extracts text, handwriting, and data from scanned documents. It goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables."
Common use cases for Textract include importing documents and forms into applications; indexing documents; classifying documents; and extracting text for natural language processing.
What kind of documents can Textract work with? Adobe PDFs and images in JPEG, PNG, or TIFF formats. Images should be at least 150 DPI. Whether the text and data you're after is printed text, scanned handwriting, form data, or in a photograph, Textract can help you get it. Textract can detect printed text and handwriting in English, Spanish, Italian, French, Portuguese, and German.
With the AWS SDK for .NET, you can ask Textract to analyze documents for text detection, analyze documents to detect form fields & table data, or analyze ID documents for identity fields.
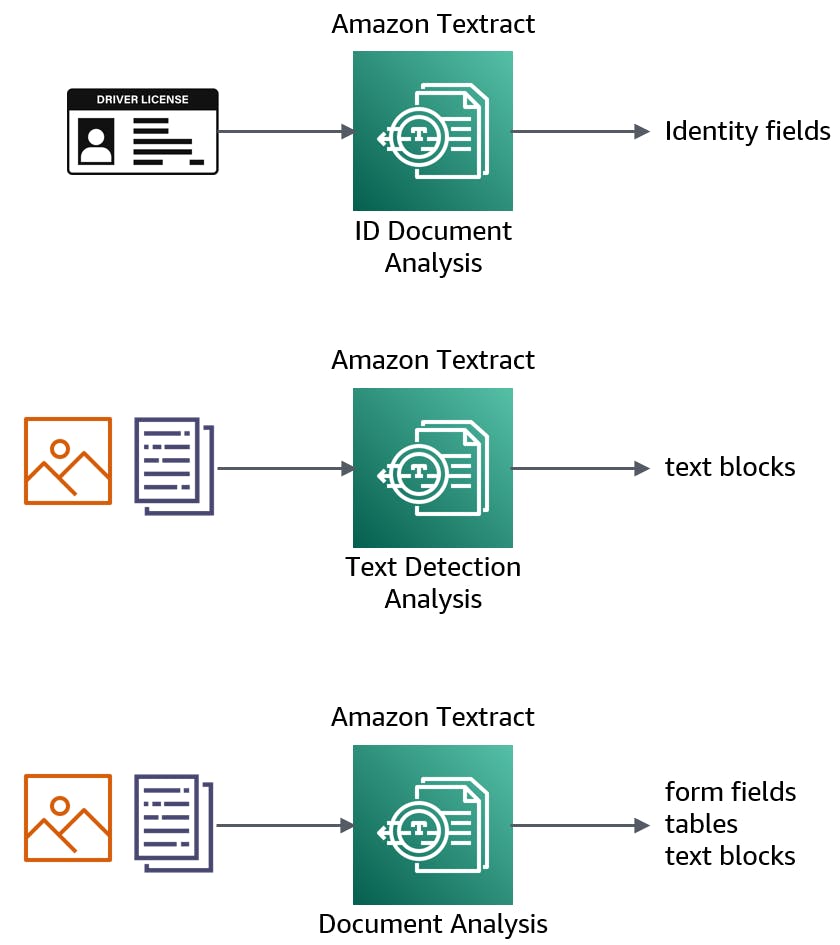
Although Textract is categorized as a Machine Learning service, you don't need to train it: Textract is ready to process your documents from Day 1. Textract can do more then merely extract text. It can recognize form fields, returning fields and values. It can recognize tables and cells. High-confidence predictions are returned in its results, and low-confidence results can undergo human review. One common way to work with Textract is through S3 buckets, where both source documents and results can be stored.
Our Hello, Textract Project
We’re going to first try out Textract through the AWS console. Then, we'll create a .NET 6 console program and use it to command Textract to process a variety of documents and display the text and data found. We'll feed Textract forms, IDs, photographs, scanned handwriting, documents, and tables to test its abilities.
One-time Setup
To experiment with Textract and .NET, you will need:
- An AWS account, and an understanding of what is included in the AWS Free Tier.
- Microsoft Visual Studio 2022. If you're using an older version of Visual Studio you won't be able to use .NET 6.
- AWS Toolkit for Visual Studio. Configure the toolkit to access your AWS account and create an IAM user.
Step 1: Set Permissions for the AWS Toolkit User
In order to perform this tutorial, your AWS Toolkit User / default AWS profile needs the necessary permissions for Textract operations. In this step, you'll update permissions for your AWS Toolkit for Visual Studio user.
Important: You should always follow the principle of least privilege when it comes to security. This blog series assumes you are working in your own developer account for learning purposes and not working with anything production-related. If you're using an organization-owned AWS account, you should coordinate with your security principal on IAM settings.
- Sign in to the AWS console. Select the region at top right you want to be working in. We're using US West (N. California).
- Navigate to the Identity and Access Management (IAM) area of the AWS Console. You can enter iam in the search box to find it.
- Click Users on the left panel and select the username you use with the AWS Toolkit for Visual Studio (you created this user when you installed and configured the toolkit).
- If not already assigned, add the built-in PowerUserAccess permission. The PowerUserAccess permission provides developers full access to AWS services and resources, but does not allow management of users and groups.
Your AWS Toolkit for Visual Studio user now has the permissions it needs to perform Textract operations.
Step 2: Use Textract in the AWS Console
In this step, you'll use Textract in the AWS console.
In the AWS console, navigate to Amazon Textract. You can enter textract in the search bar.
Select Analyze document from the left panel. You see a Sample document displayed with an analysis.
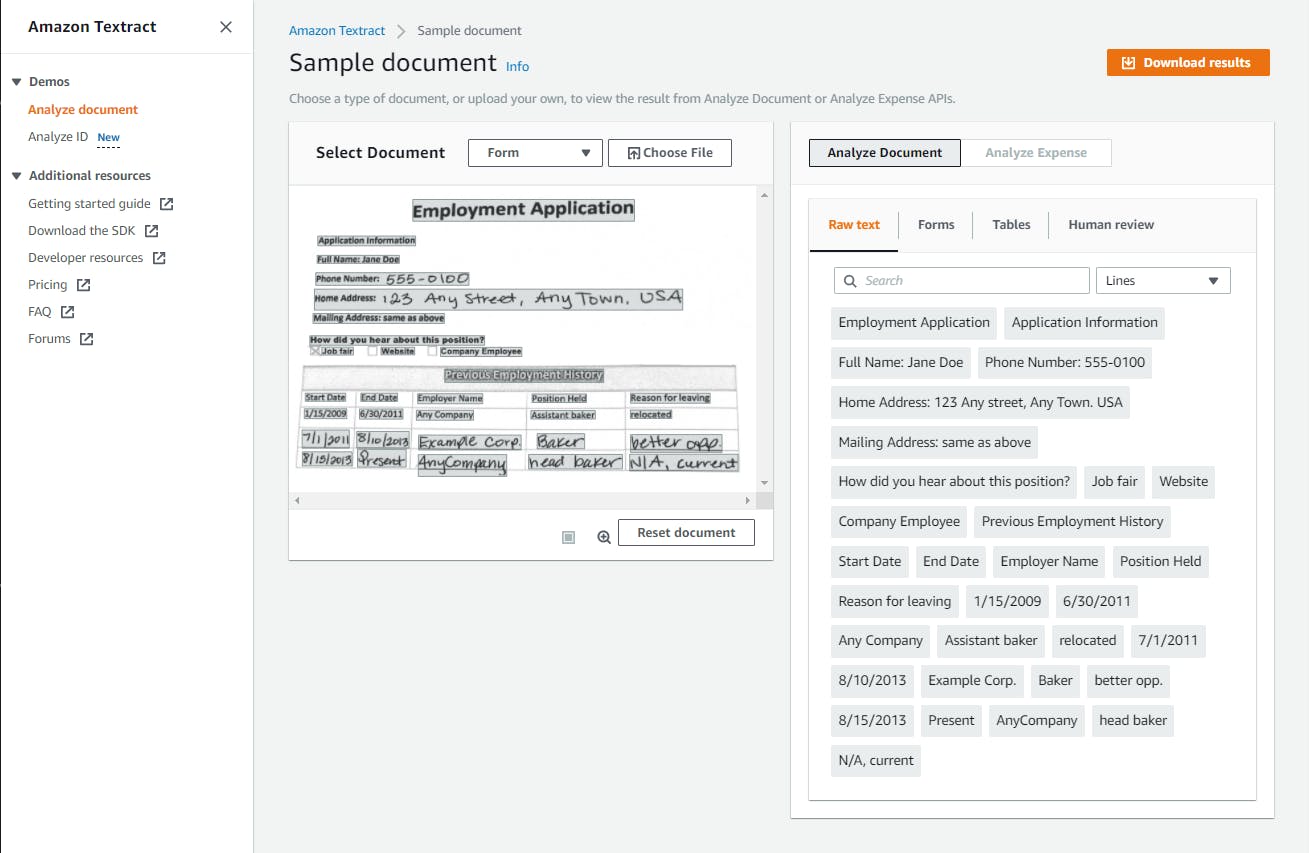
Click the Choose file button and select a document file, such as a saved PDF form, a scan, or a photograph containing text. We're using an auto repair service estimate. If this is the first time you're using Textract, you will be prompted whether to create an S3 bucket to store the file. Click Yes, create the bucket.

Wait for processing to complete, with a "Successfully created [bucketname]" message. You will see your PDF document displayed on the left, and extracted text results on the right.
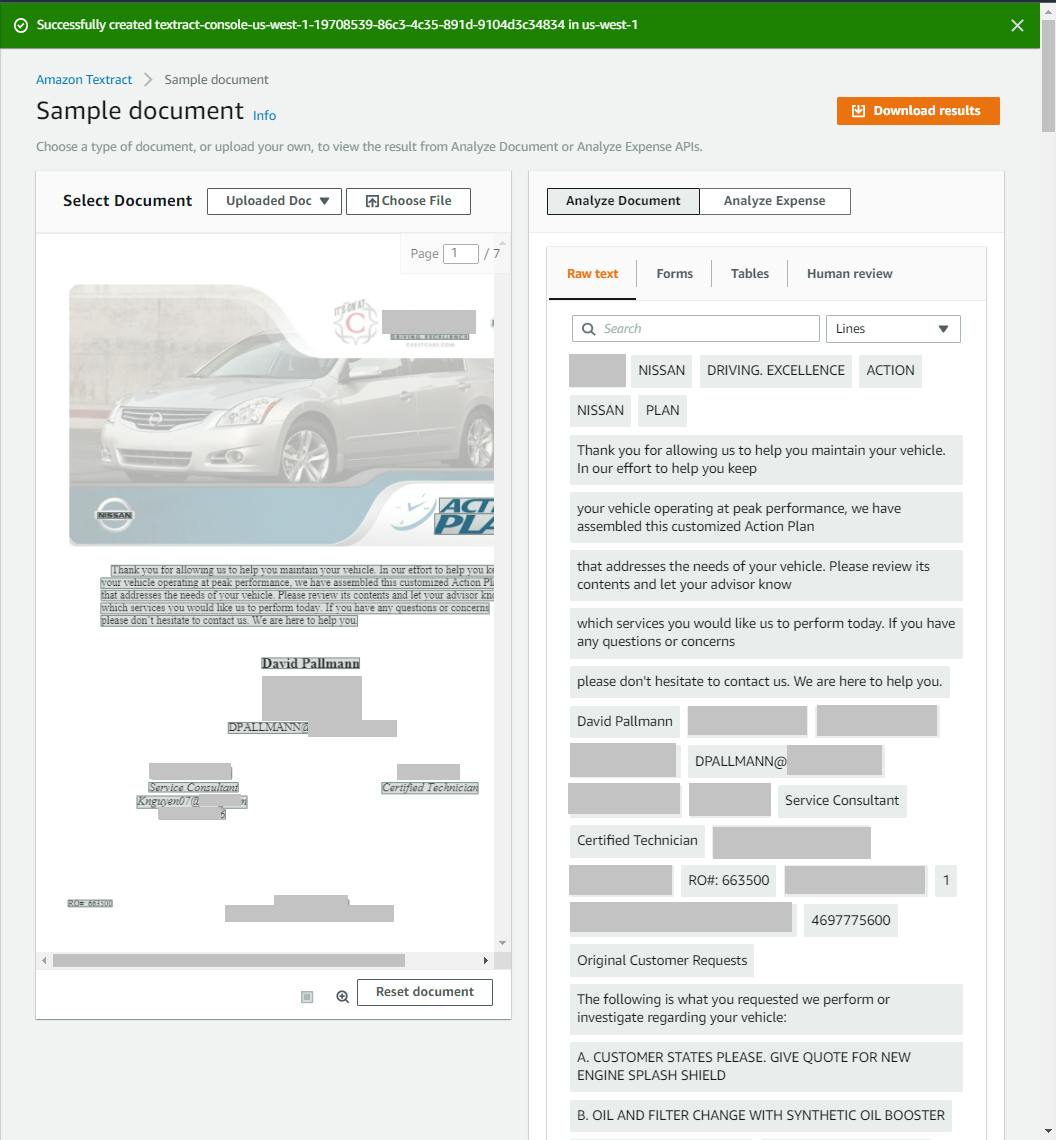
Explore the analysis panel at right to see what Textract found in your document. If your document is multi-page, you can advance through each page in the Page X of Y control. If your experience is like mine, Textract did a good job of locating the text chunks in the PDF.
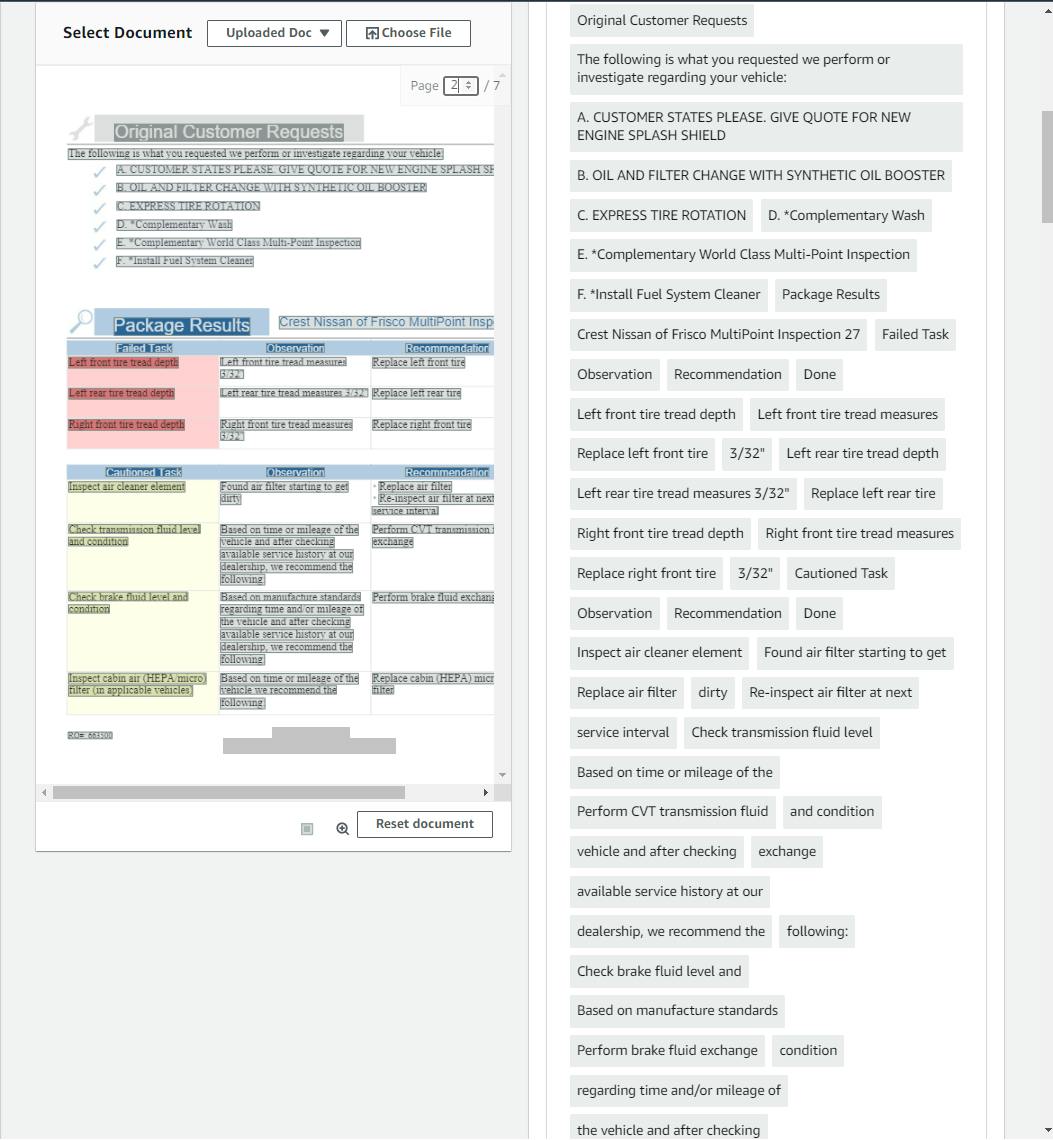
If your PDF contained form fields or tables, click the Forms tab or Tables tab in the right panel to see what Textract identified. Our test document contained several tables, and Textract located them properly.
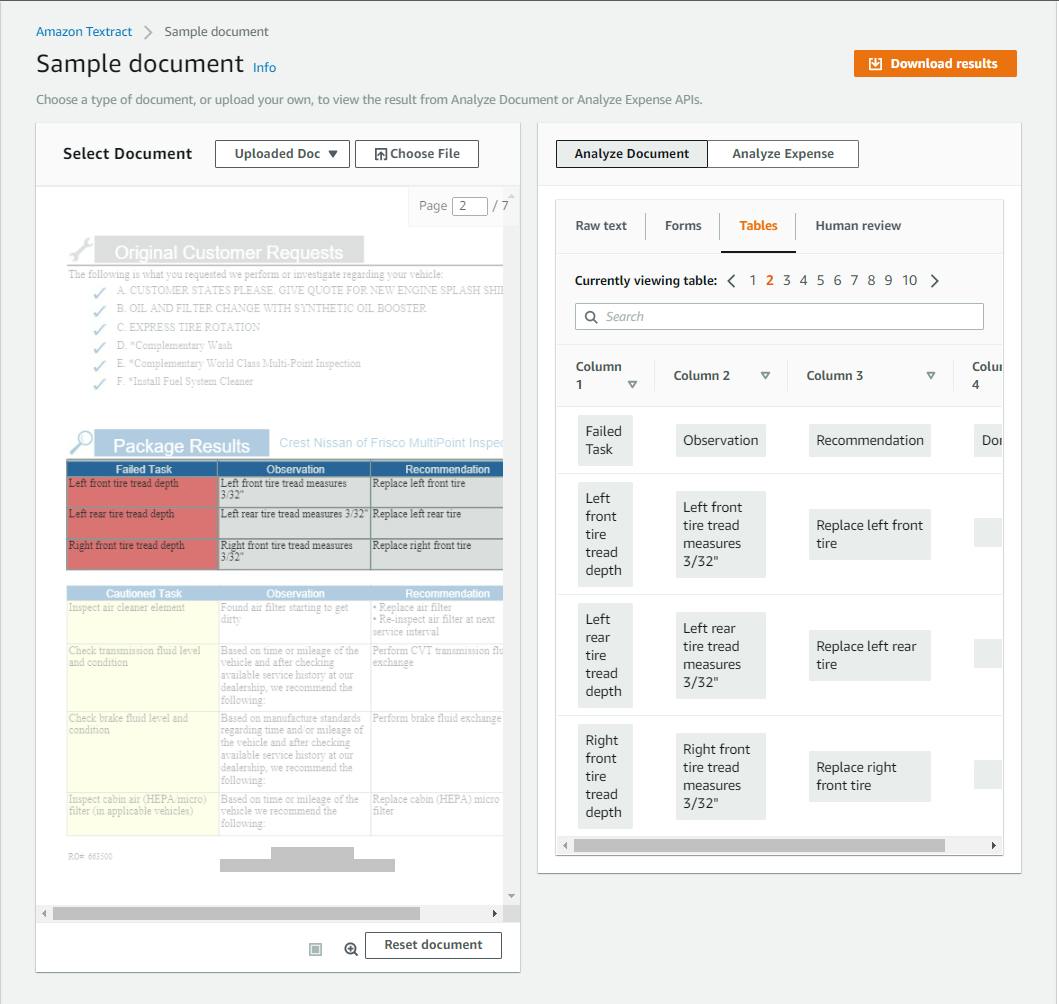
Textract has a separate facility just for processing IDs. On the left panel, click Analyze ID.
Take a picture of an ID such as a driver license, and upload it by clicking Choose document. After it is processed, you see the extracted fields on the right panel.
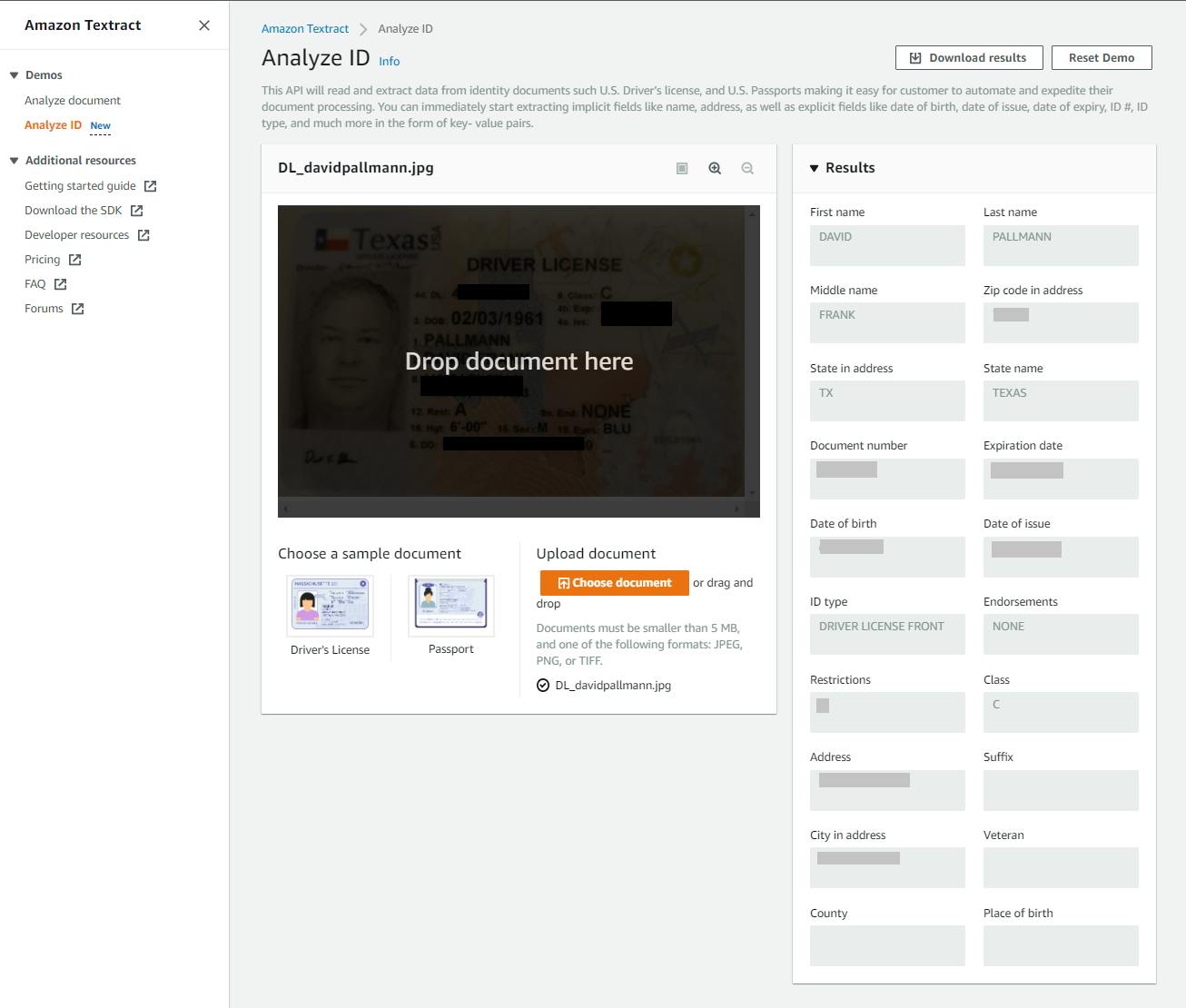
You've now seen what Textract text detection, document analysis, and ID analysis can do.
Step 3: Create an S3 Bucket
In this step, you'll create an S3 bucket for our program to upload documents to for processing by Textract.
In the AWS console, navigate to Amazon S3. You can enter s3 in the search bar.
Select Buckets in the left panel, and click Create bucket. Complete the Create bucket form as follows:
a. Enter a bucket name. We're using hello-textract.
b. Click Create bucket at bottom.
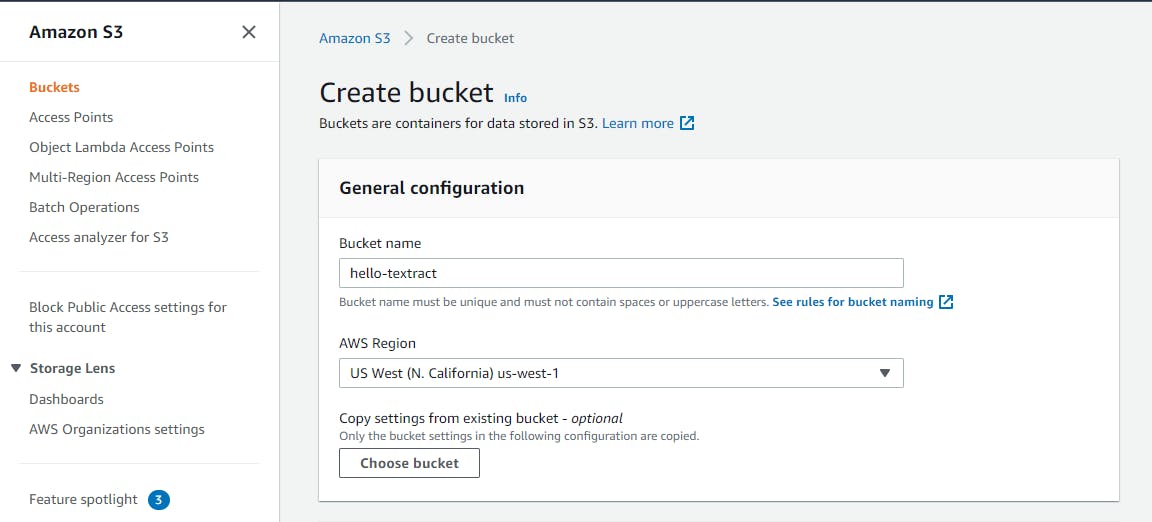
We now have an S3 bucket for our program to use.
Step 4: Create a .NET Program that Uses Textract
In this step, we'll create a .NET console program and use it to invoke Textract on various files.
Open a command/terminal window and CD to a development folder.
Enter the dotnet new command below to create a .NET 6 console program.
dotnet new console -n hello-textract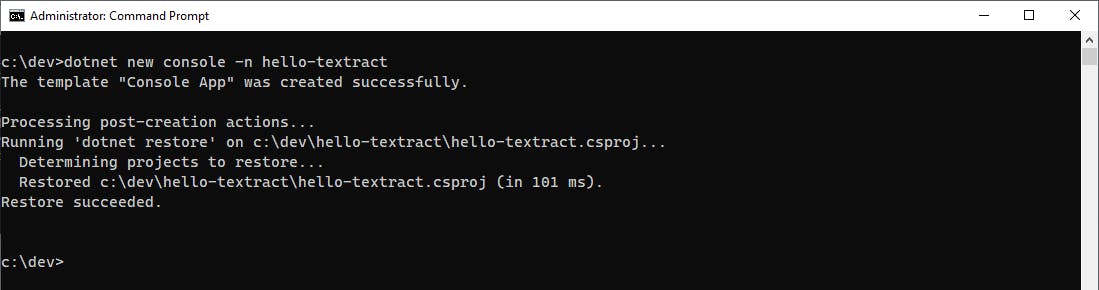
Launch Visual Studio and open the hello-textract project.
In Solution Explorer, right-click the hello-textract project and select Manage Nuget Packages....
a. Find and install the AWSSDK.Textract package.
a. Find and install the AWSSDK.S3 package.
Replace Program.cs with the code at the end of this step, and make these replacements:
a. Replace [bucketname] with the bucket name you recorded in Step 3.
b. Replace [region] with the Amazon region code for your region. For example, for our region of N. California we specify RegionEndpoint.USWest1. Save your changes.
Add a new class named TextractHelper.cs and replace its code with the code at the end of this step. We'll review how the code works after we run it.
Save your changes and build the program.
Program.cs
using Amazon;
using hello_textract;
const string bucketname = @"[bucketname]";
var region = RegionEndpoint.[region];
if (args.Length == 2)
{
var filename = args[0];
var analysisType = (args.Length > 1) ? args[1] : "text";
TextractHelper helper = new TextractHelper(bucketname, region);
switch (analysisType)
{
case "id":
await helper.AnalyzeID(filename);
Environment.Exit(1);
break;
case "text":
await helper.AnalyzeText(filename);
Environment.Exit(1);
break;
case "table":
await helper.AnalyzeTable(filename);
Environment.Exit(1);
break;
}
}
Console.WriteLine("?Invalid parameter - command line format: dotnet run -- <file> text|data|table");
TextractHelper.cs
using Amazon;
using Amazon.S3;
using Amazon.S3.Model;
using Amazon.Textract;
using Amazon.Textract.Model;
namespace hello_textract
{
public class TextractHelper
{
private string _bucketname { get; set; }
private RegionEndpoint _region { get; set; }
private AmazonTextractClient _textractClient { get; set; }
private AmazonS3Client _s3Client { get; set; }
public TextractHelper(string bucketname, RegionEndpoint region)
{
_bucketname = bucketname;
_region = region;
_textractClient = new AmazonTextractClient(_region);
_s3Client = new AmazonS3Client(_region);
}
/// <summary>
/// ID document analysis.
/// </summary>
/// <param name="filename"></param>
public async Task AnalyzeID(string filename)
{
Console.WriteLine("Start document ID analysis");
var bytes = File.ReadAllBytes(filename);
AnalyzeIDRequest request = new AnalyzeIDRequest()
{
DocumentPages = new List<Document> { new Document { Bytes = new MemoryStream(bytes) } }
};
var getDetectionResponse3 = await _textractClient.AnalyzeIDAsync(request);
foreach (var doc in getDetectionResponse3.IdentityDocuments)
{
foreach (var field in doc.IdentityDocumentFields)
{
Console.WriteLine($"{field.Type.Text}: {field.ValueDetection.Text}");
}
}
}
/// <summary>
/// Analyze document for text detection.
/// </summary>
/// <param name="filename">path to local file</param>
public async Task AnalyzeText(string filename)
{
// Upload document to S3.
var docLocation = await UploadFileToBucket(filename);
// Start a document text detection job.
Console.WriteLine("Starting document text detection job");
var startJobRequest = new StartDocumentTextDetectionRequest { DocumentLocation = docLocation };
var startJobResponse = await _textractClient.StartDocumentTextDetectionAsync(startJobRequest);
Console.WriteLine($"Job ID: {startJobResponse.JobId}");
// Wait for the job to complete.
Console.Write("Waiting for job completion");
var getResultsRequest = new GetDocumentTextDetectionRequest { JobId = startJobResponse.JobId };
GetDocumentTextDetectionResponse getResultsResponse = null!;
while ((getResultsResponse = await _textractClient.GetDocumentTextDetectionAsync(getResultsRequest)).JobStatus==JobStatus.IN_PROGRESS)
{
Console.Write(".");
Thread.Sleep(1000);
}
Console.WriteLine();
// Display detected text blocks.
if (getResultsResponse.JobStatus == JobStatus.SUCCEEDED)
{
Console.WriteLine("Detected text blocks:");
do
{
foreach (var block in getResultsResponse.Blocks)
{
Console.WriteLine($"Type {block.BlockType}, Text: {block.Text} ({block.Confidence:N0}%)");
}
if (string.IsNullOrEmpty(getResultsResponse.NextToken)) { break; }
getResultsRequest.NextToken = getResultsResponse.NextToken;
getResultsResponse = await _textractClient.GetDocumentTextDetectionAsync(getResultsRequest);
} while (!string.IsNullOrEmpty(getResultsResponse.NextToken));
}
else
{
Console.WriteLine($"ERROR: job failed - {getResultsResponse.StatusMessage}");
}
}
/// <summary>
/// Analyze document for table data.
/// </summary>
/// <param name="filename">path to local file</param>
public async Task AnalyzeTable(string filename)
{
// Upload document to S3.
var docLocation = await UploadFileToBucket(filename);
// Start a document analysis job.
Console.WriteLine("Starting document analysis job");
var startJobRequest = new StartDocumentAnalysisRequest { DocumentLocation = docLocation, FeatureTypes = { "TABLES" } };
var startJobResponse = await _textractClient.StartDocumentAnalysisAsync(startJobRequest);
Console.WriteLine($"Job ID: {startJobResponse.JobId}");
// Wait for the job to complete.
Console.Write("Waiting for job completion");
var getResultsRequest = new GetDocumentAnalysisRequest { JobId = startJobResponse.JobId };
GetDocumentAnalysisResponse getResultsResponse = null!;
while ((getResultsResponse = await _textractClient.GetDocumentAnalysisAsync(getResultsRequest)).JobStatus == JobStatus.IN_PROGRESS)
{
Console.Write(".");
Thread.Sleep(1000);
}
Console.WriteLine();
// Display detected tables.
if (getResultsResponse.JobStatus == JobStatus.SUCCEEDED)
{
do
{
var tables = from table in getResultsResponse.Blocks where table.BlockType == BlockType.TABLE select table;
var cells = from cell in getResultsResponse.Blocks where cell.BlockType == BlockType.CELL select cell;
Console.WriteLine($"Found {tables.Count()} tables and {cells.Count()} cells");
foreach(var cell in cells)
{
if (cell.ColumnIndex==1)
{
Console.WriteLine();
Console.Write("| ");
}
foreach(var rel in cell.Relationships)
{
foreach (var id in rel.Ids)
{
var cellText = (from text in getResultsResponse.Blocks where text.Id == id select text.Text).FirstOrDefault();
Console.Write($"{cellText} ");
}
}
Console.Write("| ");
}
if (string.IsNullOrEmpty(getResultsResponse.NextToken)) { break; }
getResultsRequest.NextToken = getResultsResponse.NextToken;
getResultsResponse = await _textractClient.GetDocumentAnalysisAsync(getResultsRequest);
} while (!string.IsNullOrEmpty(getResultsResponse.NextToken));
}
else
{
Console.WriteLine($"ERROR: job failed - {getResultsResponse.StatusMessage}");
}
}
/// <summary>
/// Upload local file to S3 bucket.
/// </summary>
/// <param name="filename"></param>
/// <returns>DocumentLocation object, suitable for inclusion in Textract start job requests.</returns>
private async Task<DocumentLocation> UploadFileToBucket(string filename)
{
Console.WriteLine($"Upload {filename} to {_bucketname} bucket");
var putRequest = new PutObjectRequest
{
BucketName = _bucketname,
FilePath = filename,
Key = Path.GetFileName(filename)
};
await _s3Client.PutObjectAsync(putRequest);
return new DocumentLocation
{
S3Object = new Amazon.Textract.Model.S3Object
{
Bucket = _bucketname,
Name = putRequest.Key
}
};
}
}
}
Step 5: Run the Program
In this step, we'll run our program. Our program expects two arguments. The first is filename, the path to the file to be processed. The second is the type of analysis to perform:
dotnet new -- [filename] text|id|table
| action | analysis |
| id | process an ID document and return fields |
| text | perform text detection on a document |
| table | perform document analysis and extract table values |
Go to a command/terminal window and CD to the project folder.
Run the program against some different kinds of document files (PDFs, JPEG, PNG, or TIF files) and try out the three actions.
Here are some examples:
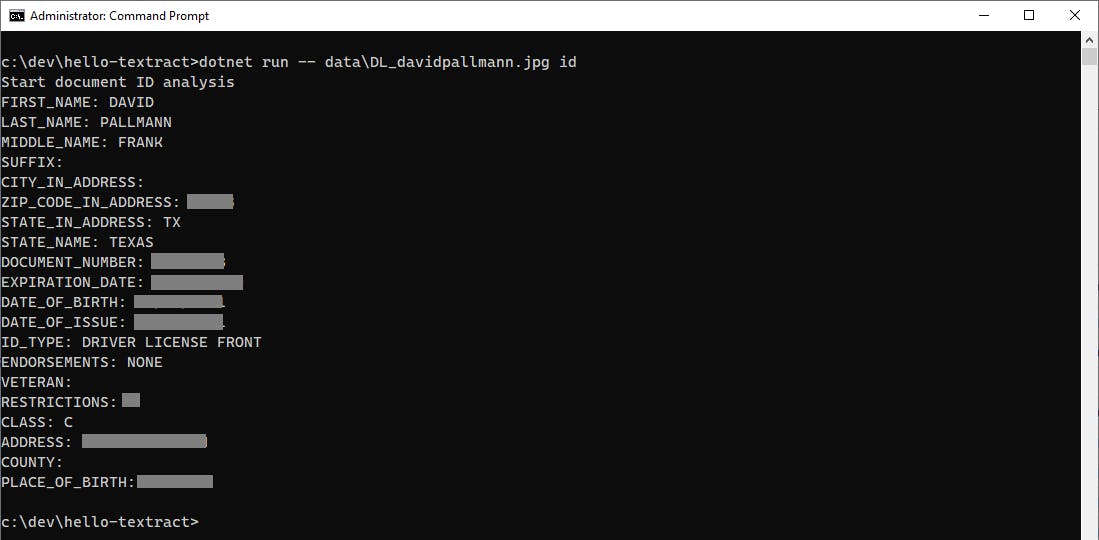
Drivers License (id analysis)
My driver's license is processed easily by Textract ID analysis, with field values returned for easy consumption.
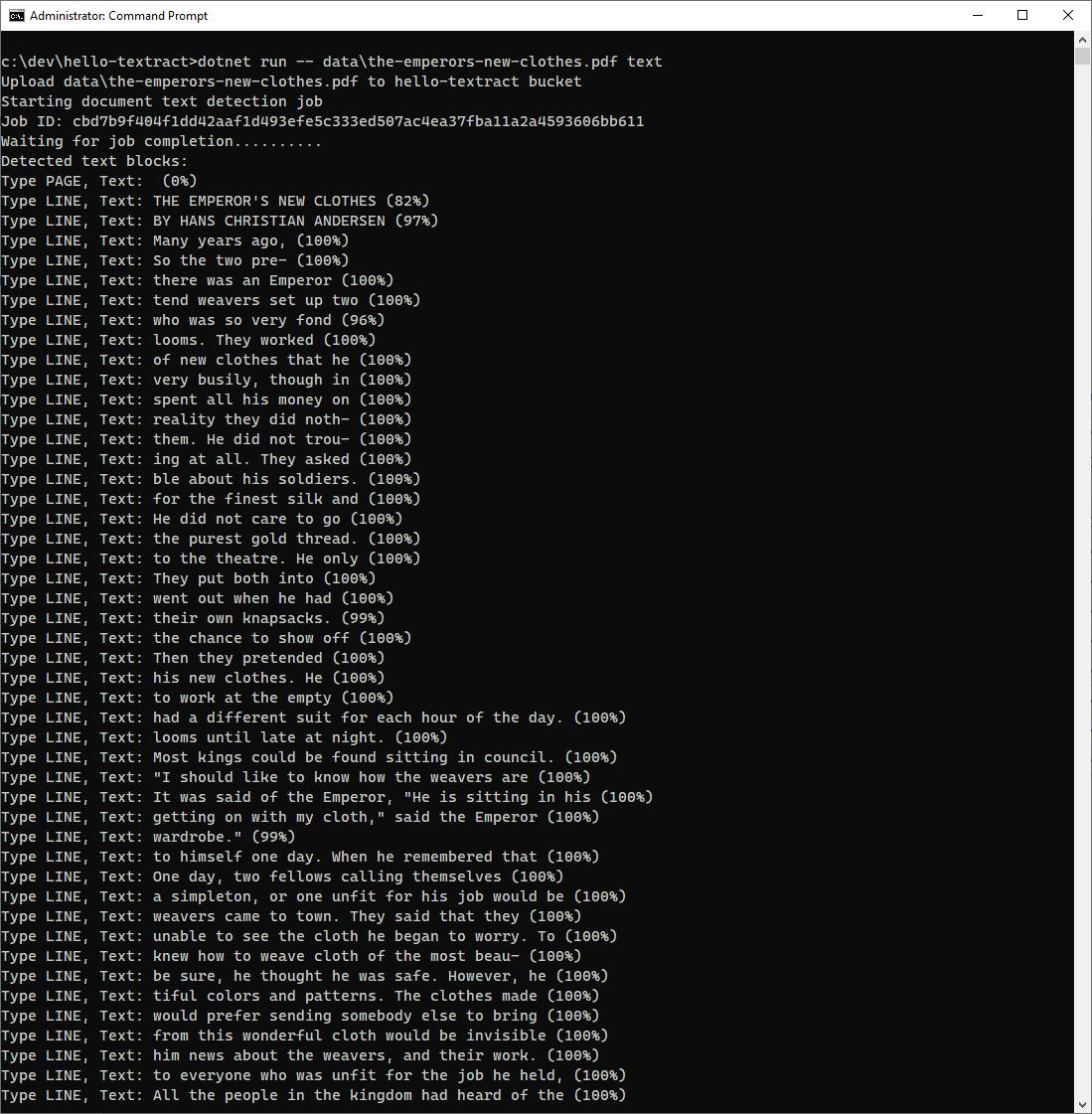
Fairy Tale (text)
This example is a PDF of a fairy tale in the public domain, The Emperor's New Clothes by Hans Christian Anderson. Textract does a good job of detecting the text with high confidence, though the split paragraph around the page 1 illustration splits some sentences.
image source: Short Fiction in the Public Domain

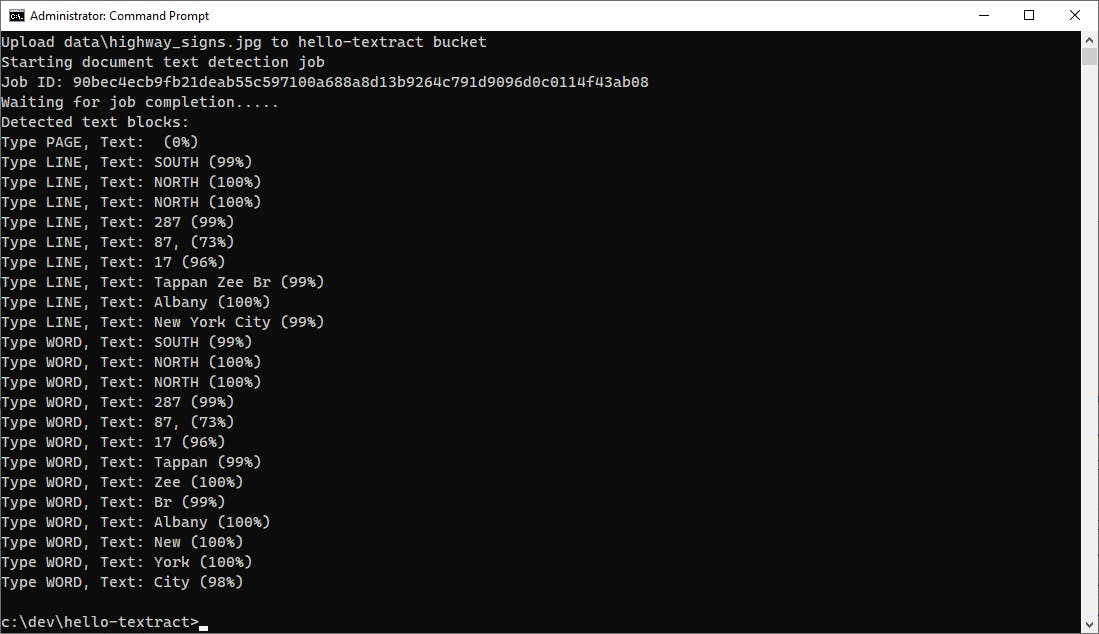
Highway road signs (text)
Textract extracts the text from this photo of highway road signs accurately. It only has a 73% confidence level in route 87, everything else is 99% or better.
image source: Wikimedia Commons

Shopping List (text)
Textract document text detection reads this handwritten shopping list accurately. It's only 58% confident about the word "jello".
image source: David Pallmann
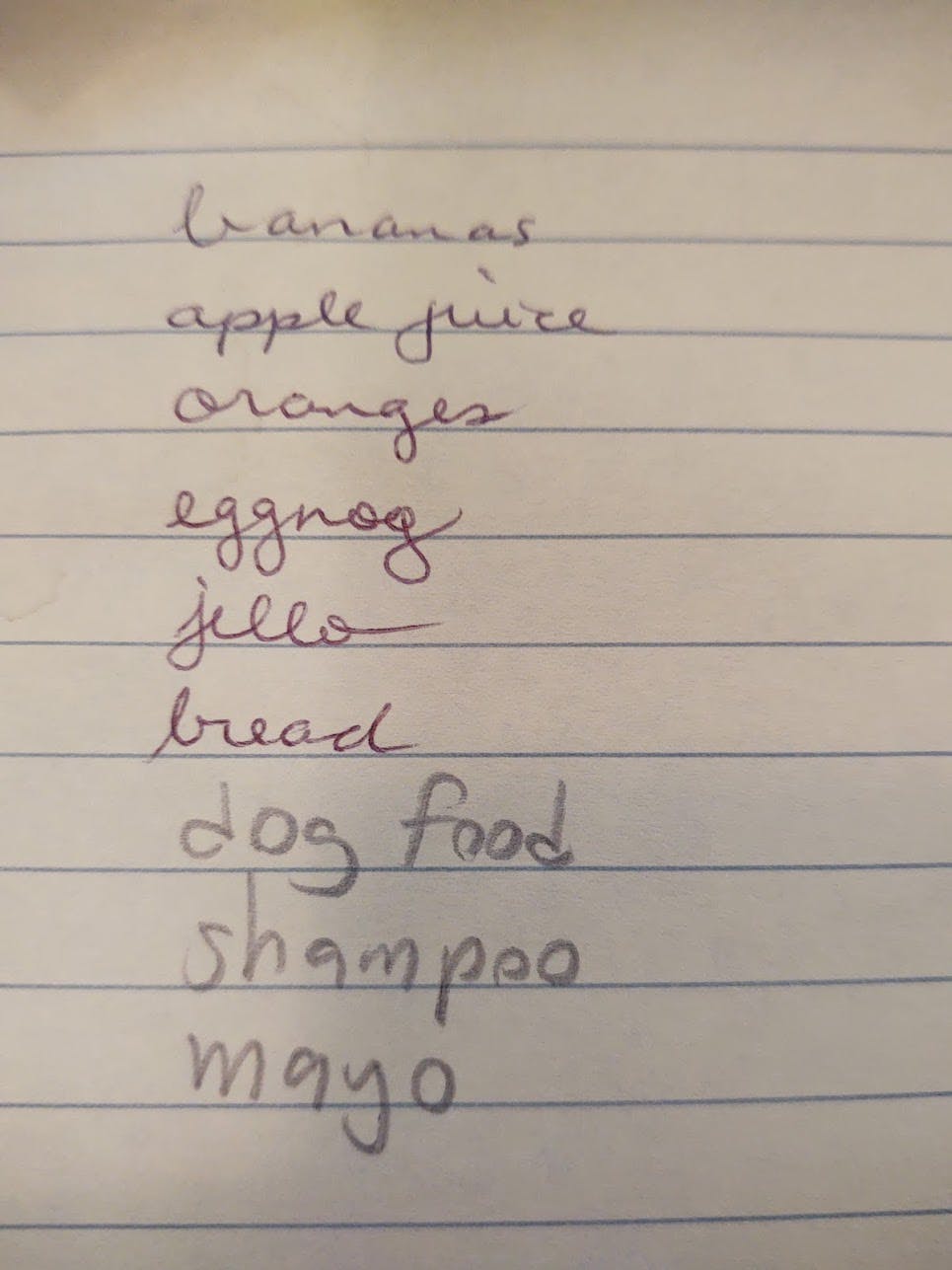
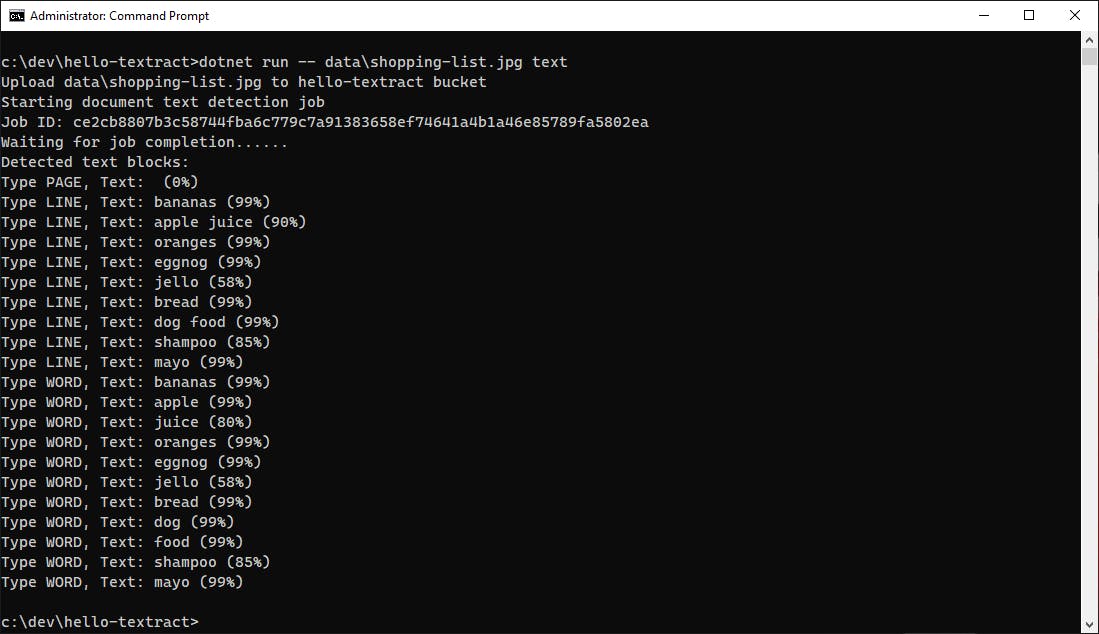
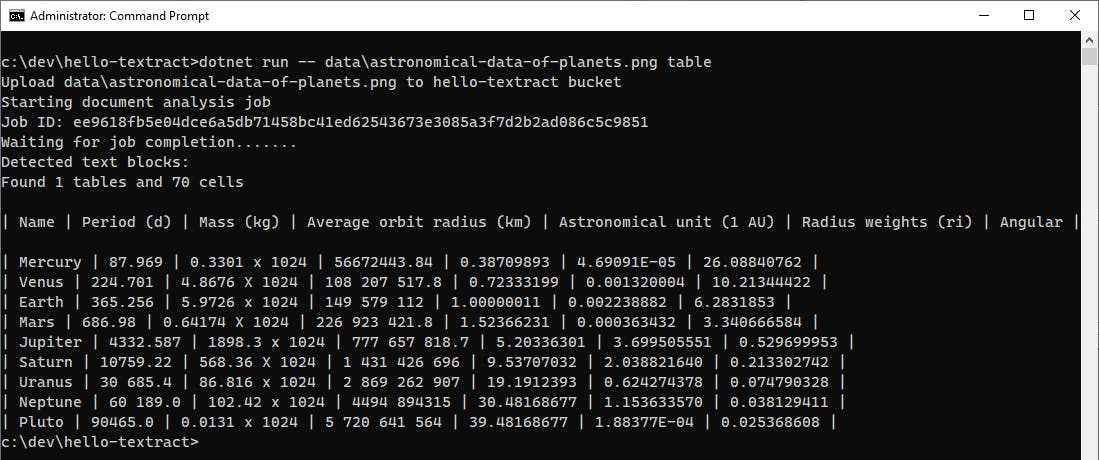
Table of Planetary Motion (table extraction)
Let's try extracting table data with the "table" action, using this image of a table of planetary motion. Textract locates the table and cells, but doesn't understand the superscripts for exponents.
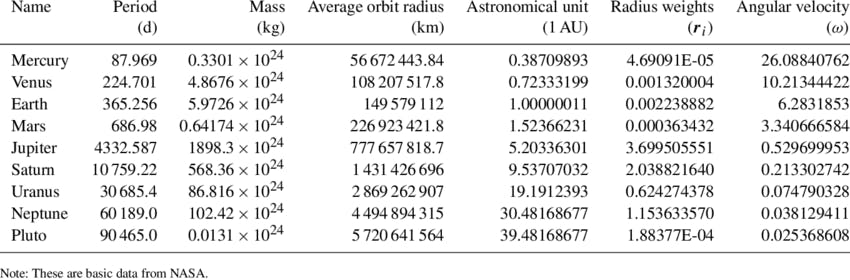
image source: Research Gate (creative commons license)
Congratulations! You've extracted id fields, text, and table data from various kinds of documents in .NET code using Amazon Textract.
Step 6: Code Walk-through
Let's take a moment to understand the code.
Program.cs simply gets the filename and action, and lets the TextractHelper class do all the work. We instantiate TextractHelper with the bucketname and region.
If the specified action is "id", our AnalyzeID method reads the document bytes and passes them to the AWS SDK for .NET's AnalyzeIDAsync method for ID document analysis. The result is a list of fields, which are displayed to the console.
If the specified action is "text", this is a bigger job that might involve multiple pages of results, so we do things more formally. Our AnalyzeText method uploads the document to S3 via the UploadFileToBucket method, receiving back a DocumentLocation object. A Textract document text detection job is started for the uploaded document. A do loop then waits for the job to complete. One or more pages of results are retrieved, containing a collection of LINE and WORD text blocks which are displayed to the console including a confidence level.
When the specified action is "table", a Textract document analysis detection job is started for the uploaded document, specifying the feature "TABLES" for table data extraction (the other option is "FORMS"). The code is similar to "text" but has to do some extra work to piece together and display the results. The results contain, in addition to PAGE, LINE, and WORD blocks, TABLE and CELL blocks. We iterate through the CELL blocks. Each CELL block found in the results contains a row and column index, but not the cell text. Instead, there is a collection of Relationships, each containing a collection of IDs. The code has to go find the text blocks with those IDs in order to show the table values.
Step 7: Shut it Down
When you're all done with hello-textract, shut it down. You don't want to accrue charges for something you're not using.
In the AWS console, navigate to Amazon S3.
Delete the objects in the S3 buckets you created in Step 2 and Step 3 and confirm. Then delete the buckets themselves.
Where to Go From Here
Whether you view computer reading as cool or eerie, there are definitely some positive use cases for the technology. In this tutorial, you got familiar with Amazon Textract and used it, first in the AWS console and then in .NET code. In .NET code, you used the AWS SDK for .NET to perform ID document analysis, text detection, and document analysis for table data extract. You saw how to upload a document to S3, submit a Textract job, and retrieve results upon completion. We did not extract form data in our tutorial, but that is very similar to extracting table data.
Textract and the other purpose-built machine learning services in AWS are some of my favorite cloud services. They provide great value, don't require setup, are easy to experiment with in the AWS console, and are just as easy to use in code.
To move forward, read up more on the service to understand its capabilities and limitations. Identify your use cases for Textract and prove them out with experimentation. Consider how other AWS machine learning services might combine with Textract.
Further Reading
AWS Documentation
Amazon Textract Developer Guide
Tutorial: Extract text and structured data with Amazon Textract
Best Practices for Amazon Textract
Amazon Textract Video Presentations
Free Machine Learning Services on AWS
Code Samples
Amazon Textract Code Samples - .NET Core
Textract .NET Github Gist by Norm Johanson
Blogs